stableKT: Enhancing Length Generalization for Attention Based Knowledge Tracing Models with Linear Biases
We added stableKT into our pyKT package.
The link is here and the API is here.
Original paper can be found at Li X, Bai Y, Guo T, et al. “Enhancing Length Generalization for Attention Based Knowledge Tracing Models with Linear Biases.” Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. 2024.
Title: stableKT: Enhancing Length Generalization for Attention Based Knowledge Tracing Models with Linear Biases
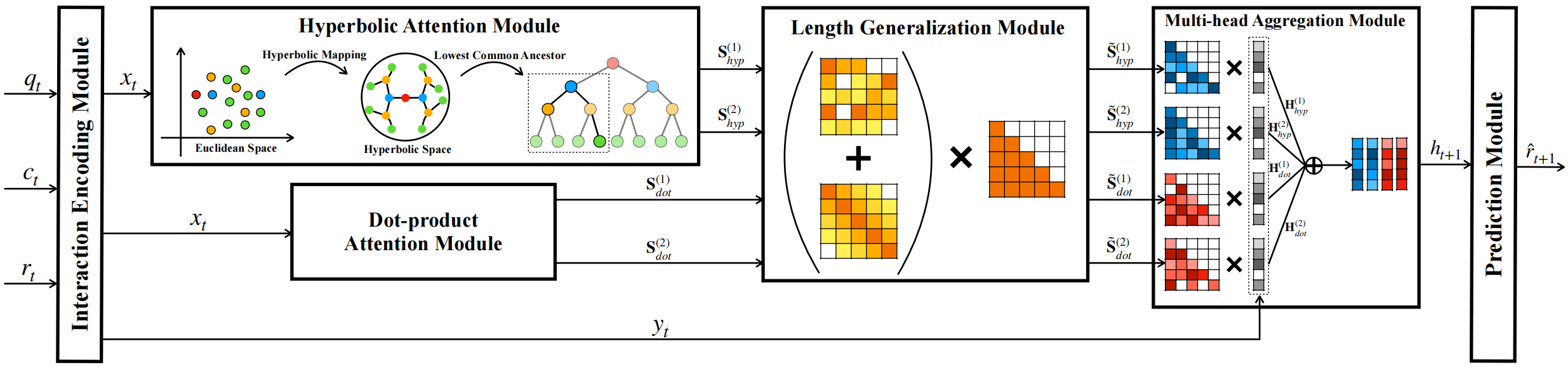
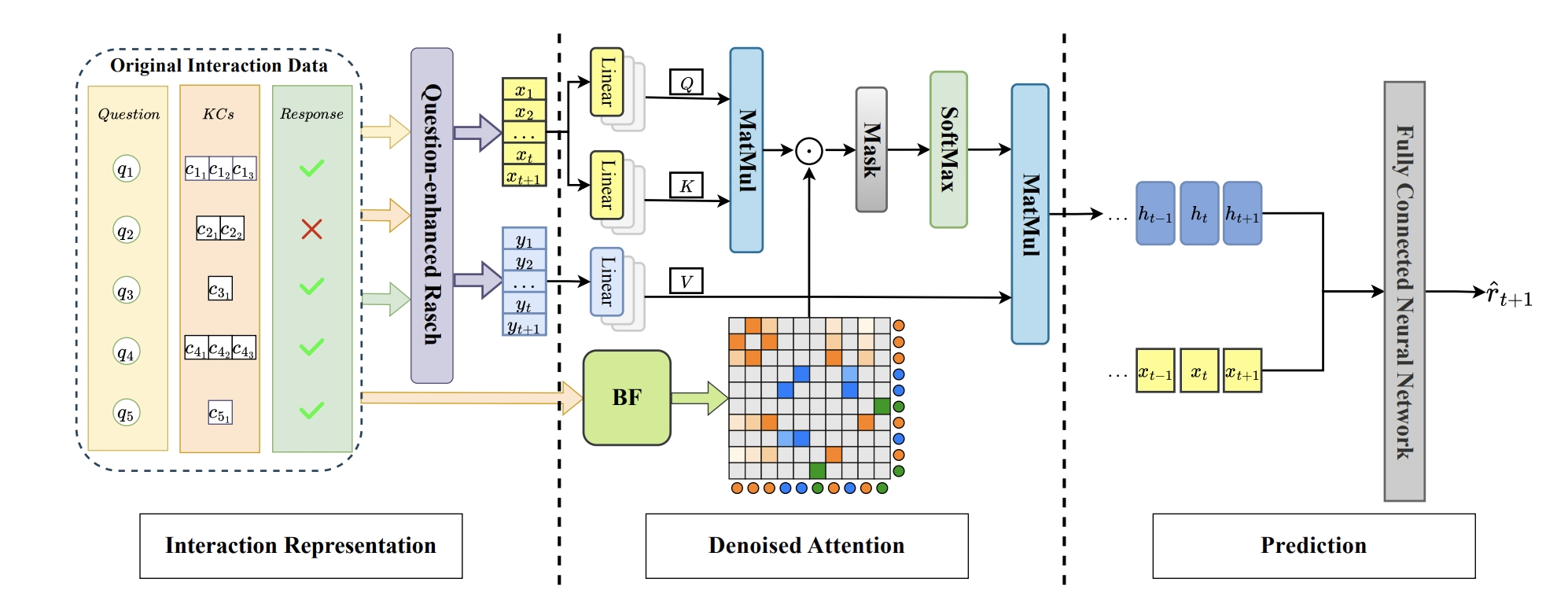
Abstract: Knowledge tracing (KT) is the task of predicting students’ future performance based on their historical learning interaction data. With the rapid advancement of attention mechanisms, many attention based KT models are developed. However, existing attention based KT models exhibit performance drops as the number of student interactions increases beyond the number of interactions on which the KT models are trained. We refer to this as the length generalization of KT model. In this paper, we propose stableKT to enhance length generalization that is able to learn from short sequences and maintain high prediction performance when generalizing on long sequences. Furthermore, we design a multi-head aggregation module to capture the complex relationships between questions and the corresponding knowledge components (KCs) by combining dot-product attention and hyperbolic attention. Experimental results on three public educational datasets show that our model exhibits robust capability of length generalization and outperforms all baseline models in terms of AUC.
{kind=link}